AWK是一种处理文本文件的语言。它将文件作为记录序列处理。在一般情况下,文件内容的每行都是一个记录。每行内容都会被分割成一系列的域,因此,我们可以认为一行的第一个词为第一个域,第二个词为第二个,以此类推。AWK程序是由一些处理特定模式的语句块构成的。AWK一次可以读取一个输入行。对每个输入行,AWK解释器会判断它是否符合程序中出现的各个模式,并执行符合的模式所对应的动作。
1、AWK概述
Awk 是一个维护和处理文本数据文件的强大语言。在文本数据有一定的格式,即每行数据包 含多个以分界符分隔的字段时,显得尤其有用。它非常强大,专为文本处理而设计。 它的名字来源于其作者的姓氏Alfred Aho, Peter Weinberger, and Brian Kernighan。
AWK有下面几个变种:
- AWK是最原始的AWK, 来自 AT&T 实验室的原始AWK
- NAWK - 来自AT&T实验室的更新和改进的AWK版本
- GAWK是GNU AWK。 所有GNU/Linux发行版都默认提供GAWK, 它与AWK和NAWK完全兼容
AWK 可以用来处理很多任务,如文字处理、格式化的文本报告等。本文中AWK如果没有特别说明,那么指的就是GAWK。

2、AWK语法
Awk的基础语法:
|
|
或
1
|
awk options '{action}' input-file |
options是可选参数,主要有-F、-f、-v:-F fs 或 --field-separator fs:字段分界符,如不指定,默认是使用空格作为分界符-f scripfile or --file scriptfile:从文件中读取awk命令,文件可以使用任意扩展名(也可不用),使用.awk扩展名便于维护-v var=value or --asign var=value:赋值一个用户定义变量
/pattern/和{action}需要用单引号包围起来/pattern是可选的,如不指定,awk将处理input-file中所有的记录,如果指定了,那么只会对处理匹配模式的记录{action}是 awk 命令, 可以是单个命令,也可以是多个命令,所有的命令必须放在{}中间input-file是指要处理的文件
|
|
3、AWK执行流程
3.1、程序结构
在典型的awk程序中包含三个区域(BEGIN区域、body区域、END区域):
1
|
awk 'BEGIN{awk commands} /pattern/{action} END{awk commands}' |
BEGIN区域:
该区域的语法:
1
|
BEGIN {awk commands} |
BEGIN区域的命令在读取文件之前、在执行body区域命令之前执行,而且仅执行一次。
这里块区域适合初始化变量、打印报告头部信息等工作。此外需要注意的是BEGIN是关键字且必须是大写的,同时BEGIN区域是可选的
BEGIN区域的命令包含在{}中,可以是一个也可以是多个命令
body区域: 该区域的语法:
1
|
/pattern/{action} |
body区域的命令会在文件读取一行就执行一次, /pattern/是可选的。
END区域 该区域的语法:
1
|
END{awk commands} |
END区域会在执行完所有操作后再执行,且只执行一次,这里适合执行一些清理操作,或打印报文结尾信息等。END是关键字需要大写,END区域可以有一个或多个命令,需要包含在 {} 中,同时END区域是可选的。
3.2、AWK 执行流程
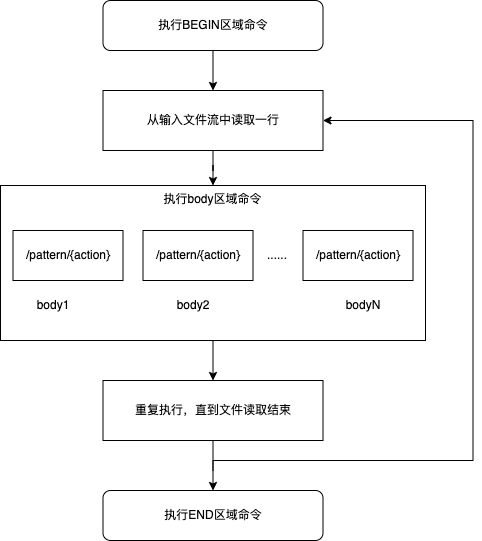
awk在读取文件并执行body区域命令前,执行BEGIN区域命令一次。然后每读取一次输入行,就会执行一次body区域命令,该区域命令可以由多个/pattern/{action}
组成,会依次执行。最后程序在结束时,会执行一次BEGIN区域命令。
|
|
4、AWK内置变量
Awk提供了很多内置变量。如awk默认分隔符是空格,可以使用-F选项来指定它,如:
|
|
这样可以通过内置变量 FS 来完成,如:
|
|
awk还提供了其他的内置变量,如:
| 变量 | 说明 |
|---|---|
| ARGC | 保存着传递给awk脚本的所有参数的个数 |
| ARGV | ARGV 是一个数组,保存着传递给awk脚本的所有参数,其索引范围从0到ARGC |
| ARGIND | ARGIND 是 ARGV 的一个索引, ARGV[ARGIND] 会返回当前正在处理的文 件名 |
| FILENAME | 当前处理的文件名(awk处理多个输入文件时很有用) |
| FS | 输入字段分隔符 |
| OFS | 输出字段分隔符 |
| RS | 记录分隔符 |
| ORS | 输出记录分隔符 |
| NF | “number of fields in the current record”, 当前记录的字段个数 |
| NR | “ordinal number of the current record”,当前记录在所有记录中的序号 |
| FNR | 当前处理的记录号,在处理一个新的文件时FNR会被重置为1,而NR不会被重置 |
| ENVIRON | ENVIRON 是一个包含所有 shell 环境变 量的数组,其索引就是环境变量的名称。 |
| IGNORECASE | IGNORECASE 的默认值是0,所有awk区分大小写。值设置为 1 时,则不区分大小写 |
| ERRNO | 当执行 I/O 操作(比如 getline)出错时,变量 ERRNO 会保存错误信息 |
| FIELDWIDTHS | 按固定宽度来解析字段,如文件中有三列,每列分别含有4、5、6个字符,那么可以设置成BEGIN {FIELDWIDTHS="4 5 6"} |
| RSTART | 被 match() 函数匹配的字符串的起始位置,如果没有匹配则为0(匹配时从1开始) |
| RLENGTH | 被 match() 函数匹配的字符串的长度 |
| SUBSEP | 数组中下标分隔符 |
|
|
5、AWK变量的操作符
和其他程序设计语言一样,awk允许在程序中设置变量。变量以字母开头,后续字符可以是数字、字符、下划线,但关键字
不能作为awk变量。变量可以直接使用而不需要事先声明,而且没有数据类型的概念,一个awk变量是number还是string
取决于变量所处的上下文。如果要初始化变量,最好在 BEGIN 区域中操作(因为 BEGIN 区域只会执行一次)
也可以使用 -v 选项对用户定义的变量进行赋值,该变量在 BEGIN 区域也是可用的,如:
1
|
$ awk -v hello=$date '{print hello}' |
awk 支持多种运算,这些运算与 C 语言基本相同。
5.1、一元操作符
| 操作符 | 描述 |
|---|---|
| + | 取正(返回数字本身) |
| - | 取反 |
| ++ | 自增 |
| – | 自减 |
5.2、算术操作符
| 操作符 | 描述 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取余 |
5.3、字符串操作符
| 操作符 | 描述 |
|---|---|
| 空格 | 空格是连字符的操作符,如str3=str2 str1 str3为str2 连接str1后的内容 |
5.4、赋值操作符
| 操作符 | 描述 |
|---|---|
| = | 赋值 |
| += | 加法赋值 |
| -= | 减法赋值 |
| *= | 乘法赋值 |
| /= | 触发赋值 |
| %/ | 取余赋值 |
5.5、比较操作符
| 操作符 | 描述 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
| && | 且 |
| || | 或 |
5.6、正则表达式操作符
| 操作符 | 描述 |
|---|---|
| ~ | 匹配 |
| !~ | 不匹配 |
6、AWK分支和循环
awk提供完备的流程控制语句类似于 C 语言:if, if-else, while, do-while, for, break, continue。
7、AWK关联数组
Awk 的数组,都是关联数组,即一个数组包含多个”索引/值”的元素。索引没必要是一系列 连续的数字,实际上,它可以使字符串或者数字,并且不需要指定数组长度。 语法:
1 2 3 4 |
arrayname[string]=value - arrayname是数组名称 - string是数组索引 - value是为数组元素赋的值 |
可以使用arrayname[index]访问数组中的某个特定元素:
|
|
7.1、判断数组元素是否存在
如果视图访问一个不存在的数组元素,awk 会自动以访问时指定的索引建立该元素,并赋予 null 值。为了避免这种情况,在使用前最后检测元素是否存在。
可以使用if语句检查元素是否存在,返回true,则表示元素存在数组中,语法:
1
|
if(index in array-name) |
|
|
7.2、遍历数组元素
可以使用for来遍历数组,语法:
1 2 |
for (var in array-name) actions |
如:
|
|
7.3、删除数组元素
可以使用 delete 语句删除数组元素,语法:
1
|
delete arrayname[index] |
如:
|
|
8、AWK函数
awk定义并支持一系列的内置函数,这使得awk提供的功能更为完善、强大。
8.1、数值函数
| 函数 | 描述 |
|---|---|
| int(n) | 返回给定参数的整数部分值 |
| log(n) | 返回给定参数的自然对数,参数 n 必须是正数,否则会抛出错误 |
| sqrt(n) | 返回指定整数的正平方根,该函数参数也必须是整数,如果传递负数将会报错 |
| exp(n) | 返回e的n次幂 |
| sin(n) | 返回 n 的正弦值,n 是弧度值 |
| cos(n) | 返回 n 的余弦值,n 是弧度值 |
| atan2(m, n) | 该函数返回 m/n 的反正切值,m 和 n 是弧度值。 |
8.2、字符串函数
| 函数 | 描述 |
|---|---|
| index | 用来获取给定字符串在输入字符串中的索引(位置) |
| length | 返回字符串的长度 |
| split(input-string,output-array,separator) | split 函数把字符串分割成单个数组元素 |
| substr(input-string,location,length) | substr 函数从字符串中取指定的部分(子串) |
| sub(original-string,replacement-string,string-variable) | 在string-variable中用replacement-string替换第一次出现的original-string |
| gsub(original-string,replacement-string,string-variable) | gsub 和 sub 类似,只是gsub 会把所有的 original-string 替换成 replacement-string |
| match(input-string, search-string) | 函数从输入字符串中检索给定的字符串(或正则表达式),当检索到字符串时,返回一个正数值 |
| tolower(input-string) | 把给定的字符串转换为小写 |
| toupper(input-string) | 把给定的字符串转换为大写 |
| printf “print format”, variable1,variable2,etc. | 格式化输出结果 |
8.3、字符串格式化
printf 可以非常灵活、简单的进行格式化输出结果,printf中可以使用的特殊字符:
| 特殊字符 | 描述 |
|---|---|
| \n | 换行 |
| \t | 制表符 |
| \v | 垂直制表符 |
| \b | 退格 |
| \r | 回车符 |
| \f | 换页 |
printf 格式化字符
| 格式化字符 | 描述 |
|---|---|
| s | 字符串 |
| c | 单个字符 |
| d | 数值 |
| e | 指数 |
| f | 浮点数 |
| g | 根据值决定使用e 或 f 中较短的输出 |
| o | 八进制 |
| x | 十六进制 |
| % | 百分号 |
printf 支持复杂的格式化控制输出,比如:
- 指定字符串宽度时,在%和格式化字符之间加上一个-,表示左对齐, 如:
|
|
- 在字符串长度不够时可以进行补0,
%05d和%.5d效果相同,如:
|
|
更多的情况如下:
| Format | Variable | Results |
|---|---|---|
| %c | 100 | “d” |
| %10c | 100 | ” d” |
| %010c | 100 | ” 000000000d” |
| %d | 10 | “10” |
| %10d | 10 | ” 10” |
| %10.4d | 10.123456789 | ” 0010” |
| %10.8d | 10.123456789 | ” 00000010” |
| %.8d | 10.123456789 | ” 00000010” |
| %010d | 10.123456789 | “0000000010” |
| %e | 987.1234567890 | “9.871235e+02” |
| %10.4e | 987.1234567890 | “9.8712e+02” |
| %10.8e | 987.1234567890 | “9.87123457e+02” |
| %f | 987.1234567890 | “987.123457” |
| %10.4f | 987.1234567890 | ” 987.1235” |
| %010.4f | 987.1234567890 | “00987.1235” |
| %10.8f | 987.1234567890 | “987.12345679” |
| %g | 987.1234567890 | “987.123” |
| %10g | 987.1234567890 | ” 987.123” |
| %10.4g | 987.1234567890 | ” 987.1” |
| %010.4g | 987.1234567890 | “00000987.1” |
| %.8g | 987.1234567890 | “987.12346” |
| %o | 987.1234567890 | “1733” |
| %10o | 987.1234567890 | ” 1733” |
| %010o | 987.1234567890 | “0000001733” |
| %.8o | 987.1234567890 | “00001733” |
| %s | 987.123 | “987.123” |
| %10s | 987.123 | ” 987.123” |
| %10.4s | 987.123 | ” 987.” |
| %010.8s | 987.123 | “000987.123” |
| %x | 987.1234567890 | “3db” |
| %10x | 987.1234567890 | ” 3db” |
| %010x | 987.1234567890 | “00000003db” |
| %.8x | 987.1234567890 | “000003db” |
|
|
8.3、自定义函数
需要编写大量代码同时又要多次重复执行其中某些片段时,可以使用自定义函数。语法:
1 2 3 4 |
function fn-name(parameters)
{
#.....
} |
fn-name: 函数名,名称规则和变量名一样,以字母开头,后续可以是字母、数值、下划线,关键字不能作为函数名parameters: 多个参数使用逗号进行分隔,也可以没有参数
8.4、位操作
和 C 语言类似,awk 也可以进行位操作。
| 操作符 | 描述 |
|---|---|
| and | 按位与 |
| or | 按位或 |
| xor | 按位异或 |
| compl | 取反, 如:15 = 01111, 15 compl = 10000 |
| lshift | 左移,函数把操作数向左位移,可以指定位移多少次,位移后右边补 0 |
| rshift | 右移,该函数把操作数向右位移,可以指定位移多少次,位移后左边补 0 |
简单的位操作示例:
|
|
8.5、时间函数
systime()函数返回系统的 POSIX 时间,即自1970 年 1 月 1 日起至今经过的 秒数。
|
|
可以使用 strftime(string) 和 strftime(string, timestamp) 函数对时间进行格式化。strftime 支持的格式标识符如下:
| 格式标识符 | 描述 |
|---|---|
| %Y | 年份的完整格式,如 2011 |
| %y | 两位数字的年份,如 2011 显示为 11 |
| %m | 两位数字月份,一月显示为 01 |
| %d | 两位数字日期,4 号显示为 04 |
| %H | 24 小时格式, 1 p.m 显示为 13 |
| %I | 12 小时格式, 1 p.m 显示为 01 |
| %M | 两位数字分钟,9 分显示为 09 |
| %S | 两位数字秒,5 秒显示为 05 |
| %c | 显示本地时间的完整格式,如:Fri May 20 21:24:25 2022 |
| %D | 简单日期格式,和%m/%d/%y 相同 |
| %F | 简单日期格式,和%Y-%m-%d 相同 |
| %T | 简单时间格式,和%H:%M:%S 相同 |
| %x | 基于本地设置的时间格式 |
| %X | 基于本地设置的时间格式 |
| %r | 简单时间格式,和%I:%M%:%S %p相同 |
| %R | 简单时间格式,和%H:%M相同 |
| %B | 月份完整单词,一月显示为 January |
| %b | 月份缩写,一月显示为 Jan |
| %p | 显示 AM 或 PM,和%l 搭配使用 |
| %a | 三位字符星期,周一显示为 Mon |
| %A | 完整的日期,周一显示为 Monday |
| %Z | 时区,太平洋地区时区显示为 PST |
| %n | 换行符 |
| %t | 制表符 |
|
|
9、AWK脚本程序
awk 和 shell 一样是一个解释型语言,也可以用来写可以执行的脚本程序。
和shell脚本类似,awk脚本以下面一行开头:
1
|
#!/path/to/awk/utility -f |
如在我的系统中,awk安装在/usr/local/bin/awk,所以我的脚本开头第一行是:
1
|
#!/usr/local/bin/awk -f |
#!,指明使用那个解释器来执行脚本中的命令/usr/local/bin/awk,解释器-f,解释器选项,用来指定读取程序文件
需要注意的是,直接指定解释器位置,有可能导致一个问题,换到其他机器,同样脚本却无法执行,因为脚本解释器可能安装在不同的目录中。更好的解决办法是用#!/usr/bin/env awk, env 会在系统PATH目录中查找awk。
编辑保存好脚本bits.awk,如:
1 2 3 4 5 6 7 8 9 10 |
#! /usr/bin/env awk -f
BEGIN{
num1=15
num2=25
print "AND: " and(num1,num2);
print "OR: " or(num1,num2);
print "XOR: " xor(num1,num2);
print "LSHIFT: " lshift(num1,2);
print "RSHIFT: " rshift(num1,2);
} |
然后,给脚本添加可自行权限:
|
|
此时就可以执行它了:
|
|
10、有趣的使用案例
10.1、只打印特殊行号的行
可以使用内置变量NR(表示当前记录在所有记录中的行号)进行处理。
myheart文件内容如下:
1 2 3 |
1 Every night in my dreams 2 I see you, I feel you 3 That is how I know you go on |
输出文件myheart的奇数行:
|
|
10.2、显示一行最后一个字段值
内置变量 NF 可以获取到一行的字段数量,使用$NF就可以获取到一行的最后一个字段值,如:
|
|
10.3、在Makefile中输出命令帮助信息
下面是来自项目kratos-layout 的Makefile:
|
|
其中help命令输出帮助信息是用awk从Makefile文件中收集注释信息生成的,提取awk命令如下:
|
|
这段awk程序中没有BEGIN和END区域命令,只有body部分,且是由两个body区域命令构成。
第一个由awk '/^[a-zA-Z\-\_0-9]+:/ { \开始的这段body区域,由一段模式匹配开始,只有匹配的行才会交给
其后的{}中命令进行执行,具体也就是第一个body区只处理Makefile中的命令行,也就是init:、config:…help:这些行。
第二个body区域中只有一行命令:lastLine = $0 , 把读取到的行保存到变量lastLine中,此时awk读取到下一行进行处理时,lastLine保存的就是它上一行的内容。
$(MAKEFILE_LIST) 指定是当前的Makefile文件
此时再回头看第一个body区域命令,就很清晰了。该区域命令,在遇到当前行是Markfile中的命令,且上一行是以#开始的注释行时,使用substr和index函数进行截取出Markfile指令(不包含:),
并使用substr截取上一行的注释内容(去掉开头的#),再使用printf 函数进行格式化输出指令和它的说明信息,%-22s以左对齐、最小22个字符宽度格式化指令进行输出,如:
1 2 3 4 5 6 7 |
init init env config generate internal proto api generate api proto build build generate generate all generate all help show help |
10.4、解析处理CSV文件
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),以纯文本形式存储表格数据(数字和文本)。 典型情况下每行一条记录,用分隔符来分隔字段。CSV格式的标准定义参见RFC 4180 。
awk 内置变量FS, 指定分隔符,也就是出现两个字段之间的部分。FS 定义了字段不是什么,而不是直接去定义字段是什么。
在对于仅仅使用分隔符(如逗号)分割数据,字段中没有嵌入的分隔符时,如文件imgs.csv内容:
|
|
对于这种情况,用FS 就可以正确解析出每个字段内容, 如:
|
|
但对于字段中嵌套了分隔符的CSV,如在双引号(double quotes)中嵌入逗号作为字段的情况,如下面的数据:
1
|
"SELECT `id`, `name`, `phone` FROM `customer` ORDER BY `id` DESC LIMIT ?, ?",saas,"17",3.146,"3.251","0","0","7.53","7530192","3.53","5" |
变量FPAT为这种情况提供了解决方案,变量 FPAT 值是一个正则表达式字符串,描述了每个字段的内容。上面的数据中,字段有用双引号包围并且其中
嵌套了逗号、没有逗号分隔符、用双引号包围没有逗号分隔符。这种情况下,可以用正则表达式 /([^,]+)|("[^"]+")/来匹配,也就是匹配不还有"的一个或多个字符,或者匹配
用双引号包围,但是包围的部分是非引号的一个或多个字符。赋值给FPAT时需要将这个正则表达式转换为字符串,并对其中的双引号进行转义,也就是:
1
|
FPAT = "([^,]+)|(\"[^\"]+\")" |
用这个来解析上面的csv数据:
|
|
上面的数据中,字段都是非空的,如果允许字段为空,那么可以把正则表达式中的+改为*来处理这种情况:
1
|
FPAT = "([^,]*)|(\"[^\"]*\")" |
10.5、查看服务器当前80端口网络连接数
netstat 是查看网络相关数据的常用命令,可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。ss 直接从Linux内核中获取TCP和连接状态信息,
效率比 netstat 好:
|
|
10.6、最常用命令列表
|
|
或
|
|